ТЕСТИРОВАНИЕ ПРОГРАММ
В целом разработчики
различают дефекты программного обеспечения и сбои. В случае сбоя программа
ведет себя не так, как ожидает пользователь. Дефект — это ошибка/неточность,
которая может быть (а может и не быть) следствием сбоя.
Общепринятая практика
состоит в том, что после завершения
продукта и до передачи его заказчику независимой группой тестировщиков
проводится тестирование ПО. Эта практика
часто выражается в виде отдельной фазы тестирования (в общем цикле
разработки ПО), которая часто используется для
компенсирования задержек, возникающих на предыдущих стадиях разработки. Другая практика состоит в том,
что тестирование начинается вместе с
началом проекта и продолжается параллельно созданию продукта до завершения
проекта. Второй путь обычно требует больших трудозатрат, но качество
тестирования при этом будет выше.
Уровни тестирования:
•
модульное тестирование. Тестируется
минимально возможный для тестирования
компонент, например отдельный класс или функция;
•
интеграционное тестирование.
Проверяется, есть ли какие- либо проблемы в интерфейсах и взаимодействии между
интегрируемыми компонентами, например, не передается информация, передается
некорректная информация;
•
системное тестирование. Тестируется
интегрированная система на ее соответствие
исходным требованиям:
—
альфа-тестирование — имитация
реальной работы с системой штатными
разработчиками либо реальная работа с системой потенциальными пользователями/заказчиком на стороне
разработчика. Часто альфа-тестирование применяется для законченного продукта в
качестве внут-
реннего приемочного тестирования. Иногда альфа тестирование выполняется под отладчиком или
с использованием окружения, которое
помогает быстро выявлять найденные
ошибки. Обнаруженные ошибки могут быть переданы тестировщикам для
дополнительного исследования в
окружении, подобном тому, в котором
будет использоваться ПО;
— бета-тестирование — в
некоторых случаях выполняется распространение версии с ограничениями (по функциональности или времени работы) для
некоторой группы
лиц с тем, чтобы убедиться, что продукт содержит достаточно мало ошибок. Иногда
бета-тестирование выполняется для того,
чтобы получить обратную связь о продукте от его будущих пользователей.
5.1. Термины и определения
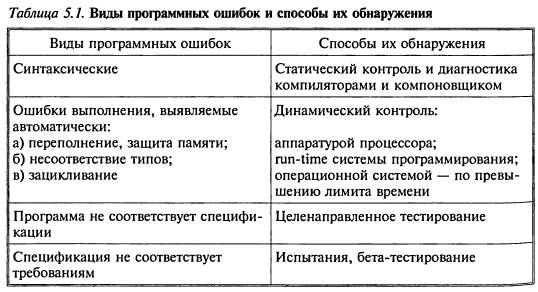
Выполнение программы с целью обнаружения ошибок называется тестированием. Виды ошибок и
способы их обнаружения приведены в табл.
5.1.
Эффективность контроля 1-го
вида зависит и от языка, и от компилятора. Контроль 2-го вида осуществляется с
помощью исключений — Exceptions и весьма полезен для проверки правдоподобности
промежуточных результатов. Тест — это набор контрольных входных данных
совместно с ожидаемыми результатами. В
число входных данных времязависимых программ
входят события и временные параметры. Ключевой вопрос — полнота
тестирования: какое количество каких тестов
гарантирует, возможно, более полную проверку программы?
Исчерпывающая проверка на всем множестве входных данных недостижима. Пример: программа, вычисляющая
функцию двух переменных: Y=f(X, Z). Если
X, Y, Z — real, то полное число тестов
(232) 2= 264= 1031 Если на
каждый тест тратить 1 мс, то 264 мс = = 800 млн лет. Следовательно:
• в любой нетривиальной программе на любой стадии ее готовности содержатся необнаруженные ошибки;
• тестирование — технико-экономическая проблема, основанная на компромиссе время — полнота.
Поэтому нужно стремиться к возможно меньшему количеству хороших тестов с желательными свойствами.
Детективность:
тест должен с большой вероятностью
обнаруживать возможные ошибки
Покрывающая способность:
один тест должен выявлять как можно больше ошибок.
Воспроизводимость:
ошибка должна выявляться независимо от изменяющихся условий (например, от
временных соотношений) — это
труднодостижимо для времязависимых программ,
результаты которых часто невоспроизводимы.
Только на основании выбранного
критерия можно определить тот момент
времени, когда конечное множество тестов
окажется достаточным для проверки программы с некоторой
полнотой (степень полноты, впрочем, определяется экспериментально). Используется два вида
критериев (табл. 5.2):
• функциональные тесты
составляются исходя из спецификации
программы;
• структурные тесты составляются
исходя из текста программы.

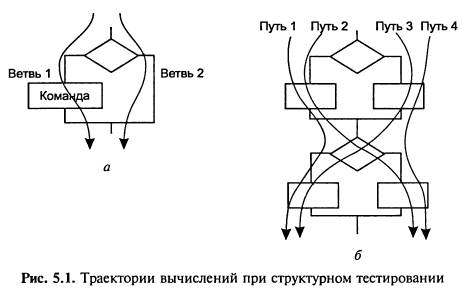
На рис. 5.1, а видно отличие
тестирования команд (достаточен один
тест) от С1 (необходимы два теста как минимум).
Рисунок 5.1, б иллюстрирует различие С1 (достаточно двух тестов,
покрывающих пути 1, 4 или 2, 3) от С2 (необходимо четыре теста для всех четырех путей). С2 недостижим
в реальных программах из-за их цикличности, поэтому ограничиваются тремя путями для каждого цикла: 0, 1 и N повторений
цикла.
Остаются проблемы назначения
классов входных/выходных данных для функционального тестирования и проектирования
тестов для структурного тестирования. Классы, как правило, назначаются исходя из семантики решаемой
задачи [6].
Рассмотрим пример. Найти
минимальный набор тестов для программы нахождения вещественных корней
квадратного уравнения ах2 + bх +
с - 0.
Решение представлено в табл. 5.3.

Таким образом, для этой программы предлагается минимальный набор функциональных тестов,
исходя из 7 классов выходных данных.
5.2. Тестирование «белого
ящика» и «черного ящика»
В терминологии профессионалов
тестирования (программного и некоторого
аппаратного обеспечения) фразы
тестирование «белого ящика» и тестирование «черного ящика» относятся к
тому, имеет ли разработчик тестов доступ к исходному коду тестируемого ПО, или
же тестирование выполняется через
пользовательский интерфейс либо прикладной программный интерфейс, предоставленный тестируемым
модулем.
При тестировании «белого ящика»
(англ. white-box testing, также говорят
— прозрачного ящика) разработчик теста имеет доступ к исходному коду и может
писать код, который связан с
библиотеками тестируемого ПО. Это типично для юнит-тестирования (англ.
unit testing), при котором тестируются только отдельные части системы. Оно
обеспечивает то, что компоненты
конструкции работоспособны и устойчивы до определенной степени.
При тестировании «черного
ящика» (англ. black-box testing) тестировщик имеет доступ к ПО только через те
же интерфейсы, что и заказчик или пользователь, либо через внешние
интерфейсы, позволяющие другому компьютеру либо другому процессу
подключиться к системе для тестирования. Например, тестирующий модуль может виртуально нажимать
клавиши или кнопки мыши в тестируемой программе с помощью механизма взаимодействия процессов с уверенностью в
том, что эти события вызывают тот же
отклик, что и реальные нажатия клавиш и кнопок мыши.
Если альфа- и бета-тестирование
относятся к стадиям до выпуска продукта
(а также, неявно, к объему тестирующего
сообщества и ограничениям на методы тестирования), тестирование «белого
ящика» и «черного ящика» имеет отношение к
способам, которыми тестировщик достигает цели.
Бета-тестирование в целом
ограничено техникой «черного ящика» (хотя постоянная часть тестировщиков
обычно продолжает тестирование «белого
ящика» параллельно бета-тестированию).
Таким образом, термин бета-тестирование может
указывать на состояние программы (ближе к выпуску, чем альфа) или может
указывать на некоторую группу тестировщиков и процесс, выполняемый этой
группой. Итак, тестировщик может продолжать
работу по тестированию «белого ящика», хотя ПО уже «в бете» (стадия), но в этом
случае он не является частью
бета-тестирования (группы/процесса).
5.3. Порядок разработки
тестов
По внешней спецификации
разрабатываются тесты [3]:
• для каждого класса входных данных;
• для граничных и особых значений входных данных.
Контролируется, все ли классы
выходных данных при этом проверяются, и добавляются при необхопимости нужные
тесты.
Разрабатываются тесты для тех
функций, которые не проверяются в п. 1.
По тексту программы проверяется,
все ли условные переходы выполнены в
каждом направлении (С1). При необходимости добавляются новые тесты.
Аналогично проверяется,
проходятся ли пути для каждого цикла: без выполнения тела, с однократным и
максимальным числом повторений.
Готовятся тесты, проверяющие
исключительные ситуации, недопустимые входные данные, аварийные ситуации.
Функциональное тестирование
дополняется здесь структурным. Классы
входных/выходных данных должны быть
определены в плане тестирования уже во внешней спецификации.
Согласно статистике 1-й и 2-й пункты обеспечивают степень охвата С1 в среднем 40—50 %. Проверка по С1
(пункт 3) обычно выявляет 90 % всех ошибок, найденных при тестировании. (Все
программное обеспечение ВВС США принимается с проверкой
по С1.)
Систематическое тестирование
предполагает также ведение журнала отладки (Bug Book), в котором фиксируется
ошибка (описание, дата обнаружения, автор модуля) и в дальнейшем — исправление
(дата, автор).
Приведем так называемые аксиомы
тестирования.
1. Тест должен быть направлен на обнаружение ошибки, а не на подтверждение
правильности программы.
2. Автор теста — не автор программы.
3. Тесты разрабатываются одновременно или до разработки программы.
4. Необходимо предсказывать ожидаемые результаты теста до его выполнения и
анализировать причины расхождения
результатов.
5. Предыдущее тестирование необходимо повторять после каждого внесения
исправлений в программу.
6. Следует повторять полное тестирование после внесения изменений в
программу или после переноса ее в другую среду.
7. В те программы, в которых обнаружено много ошибок, необходимо дополнить первоначальный набор
тестов [6].
5.4. Автоматизация
тестирования
A.Автоматизация прогона тестов
актуальна для 5-й и 6-й аксиом Майерса.
Пишутся командные файлы для запуска
программы с каждым тестом из набора и сравнением реального результата с ожидаемым. Существуют
специальные средства (например система MIL-S для PL/1 фирмы IBM). Разрабатывается
стандарт IEEE
скриптового языка для описания тестовых
наборов [3].
Б. Средства автоматизации
подготовки тестов и анализа их
результатов.
1. Генераторы случайных тестов в заданных областях входных данных.
2. Отладчики (для локализации ошибок).
3. Анализаторы динамики (profilers). Обычно входят в состав отладчиков;
применяются для проверки соответствия тестовых наборов структурным критериям
тестирования.
4. Средства автоматической генерации структурных тестов методом
«символического выполнения» Кинга.
5.5. Модульное тестирование
Модульное тестирование — это
тестирование программы на уровне отдельно взятых модулей, функций или классов.
Цель модульного тестирования заключается в выявлении
локализованных в модуле ошибок в реализации алгоритмов, а также в определении степени готовности системы к
переходу на следующий уровень разработки
и тестирования. Модульное тестирование
проводится по принципу «белого ящика», т. е. основывается на знании внутренней
структуры программы и часто включает те или иные методы анализа покрытия кода.
Модульное тестирование обычно
подразумевает создание вокруг каждого
модуля определенной среды, включающей
заглушки для всех интерфейсов тестируемого модуля. Некоторые из них могут
использоваться для подачи входных значений, другие — для анализа результатов,
присутствие третьих может быть продиктовано требованиями, накладываемыми
компилятором и сборщиком.
На уровне модульного
тестирования проще всего обнаружить дефекты, связанные с алгоритмическими
ошибками и ошибками кодирования алгоритмов, типа работы с условиями и счетчиками циклов, а также с использованием
локальных переменных и ресурсов. Ошибки, связанные с неверной трактовкой
данных, некорректной реализацией интерфейсов, совместимостью, производительностью и т. п., обычно
пропускаются на уровне модульного тестирования и выявляются на более поздних
стадиях тестирования.
Именно эффективность
обнаружения тех или иных типов дефектов
должна определять стратегию модульного тестирования, т. е. расстановку акцентов
при определении набора входных значений.
У организации, занимающейся разработкой программного
обеспечения, как правило, имеется историческая база данных (Repository)
разработок, хранящая конкретные сведения о
разработке предыдущих проектов: о версиях и сборках кода (build), зафиксированных в процессе разработки
продукта, о принятых решениях,
допущенных просчетах, ошибках, успехах и т. п. Проведя анализ характеристик
прежних проектов, подобных заказанному разработчику, можно предохранить новую
разработку от старых ошибок, например, определив типы дефектов, поиск которых
наиболее эффективен на различных этапах тестирования.
В данном случае анализируется
этап модульного тестирования. Если
анализ не дал нужной информации, например, в
случае проектов, в которых соответствующие данные не собирались, то основным правилом становится
поиск локальных дефектов, у которых код,
ресурсы и информация, вовлеченные в дефект, характерны именно для данного
модуля. В этом случае на модульном уровне ошибки, связанные, например, с неверным порядком или форматом параметров
модуля, могут быть пропущены, поскольку они вовлекают информацию, затрагивающую другие модули (а именно,
спецификацию интерфейса), в то время как ошибки в алгоритме обработки
параметров
довольно легко обнаруживаются.
Являясь по способу исполнения
структурным тестированием или тестированием «белого ящика», модульное
тестирование характеризуется степенью, в
которой тесты выполняют или покрывают
логику программы (исходный текст). Тесты, связанные со структурным
тестированием, строятся по следующим принципам:
• на основе анализа потока управления. В этом случае элементы, которые должны быть покрыты при
прохождении тестов, определяются на основе структурных критериев
тестирования СО, CI, C2. К ним относятся вершины, дуги, пути управляющего
графа программы (УГП), условия,
комбинации условий и т. п.
• на основе анализа потока данных, когда элементы, которые должны быть покрыты, определяются на
основе потока данных, т. е.
информационного графа программы.
Тестирование на основе потока управления.
Особенности использования структурных критериев тестирования СО, CI, С2 были
рассмотрены в разд. 5.2. К ним следует добавить критерий покрытия условий,
заключающийся в покрытии всех логических (булевых) условий в программе.
Критерии покрытия решений (ветвей — С1) и условий не заменяют друг друга,
поэтому на практике используется комбинированный критерий покрытия
условий/решений, совмещающий требования по покрытию и решений, и условий.
К популярным критериям
относится критерий покрытия функций программы, согласно которому каждая
функция программы должна быть вызвана
хотя бы 1 раз, и критерий
покрытия вызовов, согласно которому каждый вызов каждой функции в программе
должен быть осуществлен хотя бы 1 раз. Критерий покрытия вызовов известен также
как критерий покрытия пар вызовов (call pair coverage).
Тестирование на основе потока данных. Этот вид тестирования направлен на выявление ссылок на
неинициализированные переменные и избыточные присваивания (аномалий потока данных). Как основа для стратегии
тестирования поток данных впервые был описан в [14]. Предложенная там
стратегия требовала тестирования всех
взаимосвязей, включающих в себя ссылку
(использование) и определение переменной, на которую
указывает ссылка (т. е. требуется покрытие дут информационного графа
программы). Недостаток стратегии в том, что она не включает критерий С1 и не
гарантирует покрытия решений.
Стратегия требуемых пар [15]
также тестирует упомянутые взаимосвязи. Использование переменной в
предикате дублируется в соответствии с
числом выходов решения, и каждая из таких
требуемых взаимосвязей должна быть протестирована. К популярным критериям принадлежит критерий СР,
заключающийся в покрытии всех таких пар дуг v и w, что из дуги v достижима дуга
w, поскольку именно на дуге может произойти потеря значения переменной, которая в дальнейшем уже
не должна использоваться. Для покрытия
еще одного популярного критерия Cdu достаточно тестировать пары (вершина,
дуга), поскольку определение переменной происходит в вершине УГП, а ее использование — на дугах, исходящих из
решений, или в вычислительных вершинах.
Методы проектирования тестовых
путей для достижения заданной степени
тестированности в структурном тестировании.
Процесс построения набора тестов при структурном тестировании принято делить на три фазы:
• конструирование УГП;
• выбор тестовых путей;
• генерация тестов, соответствующих тестовым путям.
Первая фаза соответствует
статическому анализу программы, задача которого состоит в получении графа
программы и зависящего от него и от
критерия тестирования множества элементов, которые необходимо покрыть тестами.
На третьей фазе по известным
путям тестирования осуществляется поиск
подходящих тестов, реализующих прохождение этих путей.
Вторая фаза обеспечивает выбор тестовых путей. Выделяют три подхода к
построению тестовых путей:
• статические методы;
• динамические методы;
• методы реализуемых путей.
Статические методы.
Самое простое и легко реализуемое
решение — построение каждого пути посредством постепенного его удлинения
за счет добавления дуг, пока не будет достигнута выходная вершина управляющего
графа программы. Эта идея может быть усилена в так называемых адаптивных
методах, которые каждый раз добавляют
только один тестовый путь (входной
тест), используя предыдущие пути (тесты) как руководство для выбора последующих
путей в соответствии с некоторой стратегией. Чаще всего адаптивные стратегии
применяются по отношению к критерию С1. Основной недостаток статических методов
заключается в том, что не учитывается возможная
нереализуемость построенных путей тестирования.
Динамические методы.
Такие методы предполагают построение
полной системы тестов, удовлетворяющих заданному критерию, путем одновременного решения задачи
построения покрывающего множества путей
и тестовых данных. При этом можно
автоматически учитывать реализуемость или нереализуемость ранее
рассмотренных путей или их частей. Основной идеей динамических методов является подсоединение к
начальным реализуемым отрезкам путей
дальнейших их частей так, чтобы:
1) не терять при этом реализуемости вновь полученных путей;
2) покрыть требуемые элементы структуры программы.
Методы реализуемых путей.
Данная методика [16] заключается в
выделении из множества путей подмножества всех реализуемых путей. После этого
покрывающее множество путей строится из полученного подмножества реализуемых
путей.
Достоинство статических
методов состоит в сравнительно небольшом
количестве необходимых ресурсов как при
использовании, так и при разработке. Однако их реализация может содержать непредсказуемый процент брака (нереализуемых
путей).
Кроме того, в этих системах переход от покрывающего множества путей к полной системе тестов
пользователь должен осуществить вручную,
а эта работа достаточно трудоемкая.
Динамические методы требуют значительно больших ресурсов как при разработке, так и при эксплуатации, однако
увеличение затрат происходит в основном за счет разработки и эксплуатации аппарата определения реализуемости пути
(символический интерпретатор, решатель
неравенств). Достоинство этих методов
заключается в том, что их продукция имеет некоторый качественный уровень
— реализуемость путей. Методы реализуемых путей дают самый лучший результат
[33].
5.6. Интеграционное
тестирование
Интеграционное тестирование —
это тестирование части системы, состоящей из двух и более модулей. Основная
задача интеграционного тестирования — поиск дефектов, связанных с ошибками в
реализации и интерпретации интерфейсного
взаимодействия между модулями.
С технологической точки зрения
интеграционное тестирование является
количественным развитием модульного, поскольку так же, как и модульное
тестирование, оперирует интерфейсами модулей и подсистем и требует создания
тестового окружения,
включая заглушки (Stub) на месте отсутствующих модулей.
Основная разница между модульным и интеграционным тестированием состоит в целях, т. е. в типах
обнаруживаемых дефектов, которые, в свою очередь, определяют стратегию выбора
входных данных и методов анализа. В частности, на уровне интеграционного тестирования часто
применяются методы, связанные с
покрытием интерфейсов, например, вызовов функций или методов, или анализ использования
интерфейсных объектов, таких как глобальные ресурсы, средства коммуникаций, предоставляемых операционной системой.
На рис. 5.2 приведена структура
комплекса программ К, состоящего из
оттестированных на этапе модульного тестирования модулей М1, М,2
М11, М,12 М21, М22. Задача,
решаемая методом интеграционного
тестирования, — тестирование
межмодульных связей, реализующихся при исполнении программного
обеспечения комплекса К. Интеграционное тестирование использует модель «белого ящика» на модульном
уровне.
Поскольку тестировщику текст программы известен с детальностью до вызова
всех модулей, входящих в тестируемый комплекс,
применение структурных критериев на данном этапе возможно и оправданно.
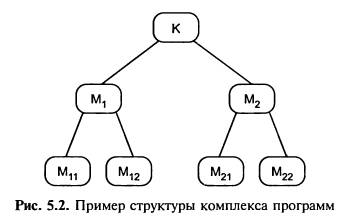
Рис. 5.2. Пример структуры комплекса программ
Интеграционное тестирование
применяется на этапе сборки модульно оттестированных модулей в единый
комплекс.
Известны два метода сборки модулей:
• монолитный, характеризующийся
одновременным объединением всех модулей
в тестируемый комплекс;
• инкрементальный,
характеризующийся пошаговым (помодульным) наращиванием комплекса программ с пошаговым тестированием собираемого
комплекса. В инкрементальном методе выделяют две стратегии добавления модулей:
— «сверху вниз» и соответствующее ему восходящее тестирование;
— «снизу вверх» и соответственно нисходящее
тестирование.
Особенности монолитного тестирования заключаются в следующем: для замены не разработанных к
моменту тестирования модулей, кроме самого верхнего (К на рис. 5.2),
необходимо дополнительно разрабатывать
драйверы (test driver) и/или заглушки(stub) [9], замещающие отсутствующие на
момент сеанса тестирования модули нижних
уровней.
Сравнение монолитного и
интегрального подходов дает следующие
результаты.
Монолитное тестирование требует
больших трудозатрат, связанных с дополнительной разработкой драйверов и
заглушек и со сложностью идентификации ошибок, проявляющихся в пространстве собранного кода.
Пошаговое тестирование связано
с меньшей трудоемкостью идентификации ошибок за счет постепенного
наращивания объема тестируемого кода и
соответственно локализации
добавленной области тестируемого кода.
Монолитное тестирование предоставляет
большие возможности распараллеливания
работ, особенно на начальной фазе тестирования.
Особенности нисходящего
тестирования заключаются в следующем:
организация среды для исполняемой очередности
вызовов оттестированными модулями тестируемых модулей, постоянная разработка и использование
заглушек, организация приоритетного
тестирования модулей, содержащих операции обмена с окружением, или модулей,
критичных для тестируемого алгоритма.
Например, порядок тестирования комплекса К (см. рис. 5.2) при нисходящем
тестировании может быть таким, как показано в примере 5.3, где тестовый набор,
разработанный для модуля Mi, обозначен как XYi =
(X, Y)i.
1) К -> XYk
2) М1 -> XY1
3)M11->XY
11
4) М2
-> XY2
5) М22
-> XY 22
6) M21
-> XY21
7) M12->
XY 12
Пример 5.1.
Возможный порядок тестов при нисходящем тестировании (html, txt).
Недостатки нисходящего
тестирования:
• проблема разработки достаточно «интеллектуальных» заглушек, т. е. заглушек, способных к использованию
при моделировании различных режимов работы комплекса,
необходимых для тестирования;
• сложность организации и разработки среды для реализации исполнения
модулей в нужной последовательности;
• параллельная разработка модулей верхних и нижних уровней приводит к не всегда эффективной
реализации модулей из-за подстройки
(специализации) еще не
тестированных модулей нижних уровней к уже оттестированным модулям верхних уровней.
Особенности восходящего
тестирования в организации
порядка сборки и перехода к тестированию модулей, соответствующему порядку их реализации.
Например, порядок тестирования комплекса К (см. рис. 5.2) при восходящем
тестировании может быть следующим (см.
пример 5.4).
1)М11->ХУ11
2) M12
-> XY12
3) Мi
-> XYi
4) М21
-> XY21
5) M2(M21,
Stub(M22))
-> XY2
6) К(М1 ,M2(M21,
Stub(M22))
-> XYk
7) М22
-> XY22
8) М2 -*
XY2
9) К -> XYk
Пример 5.2. Возможный порядок тестов при восходящем тестировании.
Недостатки восходящего тестирования:
• запаздывание проверки концептуальных особенностей тестируемого комплекса;
• необходимость в разработке и использовании драйверов [33].
5.7. Системное тестирование
Системное тестирование
качественно отличается от
интеграционного и модульного уровней. Системное тестирование рассматривает тестируемую систему в целом и
оперирует на уровне пользовательских интерфейсов, в отличие от последних
фаз
интеграционного тестирования, которое оперирует на уровне интерфейсов модулей. Различны и цели этих
уровней тестирования. На уровне системы часто
сложно и малоэффективно анализировать
прохождение тестовых траекторий внутри программы
или отслеживать правильность работы конкретных функций.
Основная задача системного тестирования — выявления дефектов, связанных с
работой системы в целом, таких как неверное
использование ресурсов системы, непредусмотренные комбинации данных
пользовательского уровня, несовместимость с
окружением, непредусмотренные сценарии использования, отсутствующая или неверная функциональность,
неудобство в применении и т. п.
Системное тестирование
производится над проектом в целом с помощью метода «черного ящика». Структура
программы не имеет никакого значения, для проверки доступны только входы и
выходы, видимые пользователю. Тестированию подлежат коды и пользовательская
документация.
Категории тестов системного
тестирования:
1. Полнота решения функциональных задач.
2. Стрессовое тестирование — на предельных объемах нагрузки входного потока.
3. Корректность использования ресурсов (утечка памяти, возврат ресурсов).
4. Оценка производительности.
5. Эффективность защиты от искажения данных и некорректных действий.
6. Проверка инсталляции и конфигурации на разных платформах.
7. Корректность документации.
Поскольку системное
тестирование проводится на
пользовательских интерфейсах, создается иллюзия того, что построение
специальной системы автоматизации тестирования не всегда необходимо. Однако объемы данных на этом уровне
таковы, что
обычно более эффективным подходом является полная или частичная автоматизация тестирования, что
приводит к созданию тестовой системы, гораздо более сложной, чем система тестирования, применяемая на уровне
тестирования модулей или их комбинаций.
5.8. Эффективность и
оптимизация программ
Эффективными считаются
программы, требующие минимального
времени выполнения и/или минимального объема оперативной памяти. Особые
требования к эффективности
программного обеспечения предъявляют при наличии ограничений (на время
реакции системы, на объем оперативной памяти и т. п.). В случаях, когда
обеспечение эффективности не требует серьезных временных и трудовых затрат, а
также не приводит к
существенному ухудшению технологических свойств, необходимо это требование иметь в виду [7].
Разумный подход к обеспечению
эффективности разрабатываемого
программного обеспечения состоит в том, чтобы в
первую очередь оптимизировать те фрагменты программы, которые
существенно влияют на характеристики эффективности. Для
уменьшения времени выполнения некоторой программы в первую очередь следует проанализировать
циклические фрагменты с большим количеством повторений: экономия времени выполнения одной итерации цикла будет
умножена на количество итераций.
Не следует забывать и о
том, что многие способы снижения временных затрат приводят к увеличению
емкостных и, наоборот, уменьшение объема
памяти может потребовать
дополнительного времени на обработку.
И тем более не следует
«платить» за увеличение эффективности
снижением технологичности разрабатываемого программного обеспечения. Исключения возможны
лишь при очень жестких требованиях и наличии соответствующего контроля за
качеством.
Частично проблему
эффективности программ решают за программиста компиляторы.
Средства оптимизации,
используемые компиляторами, делят на две группы:
• машинно-зависимые, т. е.
ориентированные на конкретный машинный язык, выполняют оптимизацию кодов
на уровне машинных команд, например,
исключение лишних
пересылок, использование более эффективных команд и т. п.
• машинно-независимые выполняют
оптимизацию на уровне входного языка, например, вынесение вычислений константных (независящих от индекса цикла)
выражений из
циклов и т. п.
Естественно, нельзя
вмешаться в работу компилятора, но
существует много возможностей оптимизации программы на уровне команд.
Способы экономии памяти. Принятие мер по
экономии памяти предполагает, что в
каких-то случаях эта память неэкономно использовалась. Учитывая, что
анализировать имеет смысл только
операции размещения данных, существенно влияющие на характеристику эффективности, следует
обращать особое внимание на выделение
памяти под данные структурных типов
(массивов, записей, объектов и т. п.).
Прежде всего при наличии
ограничений на использование памяти следует выбирать алгоритмы обработки, не
требующие дублирования исходных данных структурных типов в процессе обработки.
Примером могут служить алгоритмы сортировки
массивов, выполняющие операцию в заданном массиве, например хорошо
известная сортировка методом «пузырька».
Если в программе необходимы
большие массивы, используемые
ограниченное время, то их можно размещать в
динамической памяти и удалять при завершении обработки.
Также следует помнить, что
при передаче структурных данных в
подпрограмму «по значению» копии этих данных
размещаются в стеке. Избежать копирования иногда удается, если передавать данные «по ссылке», но как
неизменяемые (описанные
const). В последнем случае в стеке размещается только адрес данных,
например:
Type Mas.4iv array [I. 100] of real;
function Summa (Const a:Massiv; .)
Способы уменьшения времени выполнения. Как уже упоминалось выше, для уменьшения времени
выполнения в первую очередь необходимо
анализировать циклические участки
программы с большим количеством повторений. При их написании необходимо по возможности:
•
выносить вычисление константных, т. е. не зависящих от
параметров цикла, выражений из циклов;
•
избегать «длинных» операций умножения и деления, заменяя их сложением, вычитанием и сдвигами;
•
минимизировать преобразования типов в выражениях;
•
оптимизировать запись условных выражений — исключать
лишние проверки;
•
исключать многократные обращения к элементам массивов по
индексам (особенно многомерных, так как при
вычислении адреса элемента используются операции умножения на значение
индексов), первый раз прочитав из памяти элемент массива, следует запомнить его
в скалярной переменной и использовать в
нужных местах;
•
избегать использования различных типов в выражении и т.
п.
Рассмотрим следующие примеры.
Пример 5.3. Пусть имеется цикл следующей структуры (Pascal):
for у: 0 to 99 do
for x: 0 to 99 do
а [320*х+у] S [k,l];
В этом цикле операции
умножения и обращения к элементу S[k] выполняются 10 000 раз.
Оптимизируем цикл, используя, что 320 = 28 + 26:
ski: =S [k,l]; {выносим обращение к элементу массива из цикла}
for x: 0 to 99 do (меняем циклы местами}
begin
х shl 8 + х shl 6; {умножение заменяем на сдвиги и выносим из цикла)
for у; 0 to 99 do
a [i+y] =skl;
end;
В результате вместо 10 000 операций умножения будут выполняться 200 операций сдвига, а их время
приблизительно сравнимо со временем выполнения операции сложения.
Обращение к элементу массива S[k] будет выполнено 1 раз.
Пример 5.4. Пусть имеется цикл, в теле которого реализовано сложное условие:
for k: 2 to n do
begin
ifx[k] > ук then S: S+y[k]-x [к];
if (x [k]< = yk) and (y[k]<yk) then S: = S+yk-x[k];
end;...
В этом цикле можно убрать лишние проверки:
for k: =2 to n do
begin
ifx [k]>yk then S:=S+y[к]-х[к]
else
ify[k]<yk then S: =S+yk-x [k];
end;
Обратите внимание на то,
что в примере 5.3 понять, что делает
программа, стало сложнее, а в примере 5.4 — практически нет. Следовательно,
оптимизация, выполненная в первом
случае, может ухудшить технологичность программы, а потому не очень
желательна.